5-19 3,159 views
Hadoop Java版本
https://cwiki.apache.org/confluence/display/HADOOP/Hadoop+Java+Versions- Apache Hadoop 3.x现在仅支持Java 8
- 从2.7.x到2.x的Apache Hadoop支持Java 7和8
- Java 11支持正在进行中:
Hadoop 集群文档
https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/SingleCluster.html#Supported_Platforms
HDFS文档
https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html
hdfs流程:https://zhuanlan.zhihu.com/p/28614742
单实例安装教程:https://www.edureka.co/blog/install-hadoop-single-node-hadoop-cluster
HDFS安装步骤
下载地址:https://hadoop.apache.org/releases.html
https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-2.10.0/hadoop-2.10.0-src.tar.gz
参考文档:https://www.edureka.co/blog/setting-up-a-multi-node-cluster-in-hadoop-2-x/1.先决条件
2台机器
- 192.168.1.2 主
- 192.168.1.3 从
VIRTUAL BOX:用于在其上安装操作系统。
操作系统:您可以在基于Linux的操作系统上安装Hadoop。Ubuntu和CentOS非常常用。在本教程中,我们正在使用CentOS。
JAVA:您需要在系统上安装Java 8软件包。
HADOOP:您需要Hadoop 2.10.0软件包。
Hadoop 2.x中的多节点集群
从Hadoop教程系列的上一个博客中 ,我们学习了如何设置Hadoop单节点集群。现在,我将展示如何设置Hadoop多节点集群。Hadoop中的多节点群集在分布式Hadoop环境中包含两个或多个DataNode。这在组织中实际上用于存储和分析其PB和Exabyte的数据。 学习设置多节点群集使您更接近急需的Hadoop认证。
在这里,我们采用两台机器- 主服务器和从服务器。在两台计算机上,一个Datanode将正在运行。
让我们开始在Hadoop中设置多节点群集。
注释 127.0.0.1
主IP:192.168.1.2
从站IP:192.168.1.3
2.安装Hadoop(主从节点都要安装)
$ wget https://www.strategylions.com.au/mirror/hadoop/common/hadoop-2.10.0/hadoop-2.10.0.tar.gz
#在主从服务器的 /etc/hosts 添加
192.168.1.2 master
192.168.1.3 slave
127.0.0.1 192.168.1.2 localhost
#在从服务器的 /etc/hosts 添加
192.168.1.2 master
192.168.1.3 slave
127.0.0.1 192.168.1.3 localhost3.提取Hadoop tar文件。
$ tar -xvf hadoop-2.10.0.tar.gz
$ mv hadoop-2.10.0 /usr/local/
4.在bash文件(.bashrc)中添加Hadoop和Java路径。
$ vi /root/.bashrc
# user specific aliases and functions
export HADOOP_HOME=/usr/local/hadoop-2.10.0
export HADOOP_CONF_DIR=/usr/local/hadoop-2.10.0/etc/hadoop
export HADOOP_MAPRED_HOME=/usr/local/hadoop-2.10.0
export HADOOP_COMMON_HOME=/usr/local/hadoop-2.10.0
export HADOOP_HDFS_HOME=/usr/local/hadoop-2.10.0
export YARN_HOME=/usr/local/hadoop-2.10.0
export PATH=$PATH:/usr/local/hadoop-2.10.0/bin
#set JAVA_HOME
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.242.b08-0.el7_7.x86_64
export PATH=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.242.b08-0.el7_7.x86_64/jre/bin/java:$PATH
# 让配置生效
$ source /root/.bashrc
#为了确保Java和Hadoop已正确安装在您的系统上,并且可以通过终端进行访问,请执行java -version和hadoop version命令。
$ java -version
$ hadoop version
4.在主节点中创建SSH密钥。(当要求您输入文件名以保存密钥时,请按Enter键)。
# 在主节点生成秘钥
$ ssh-keygen -t rsa -P "" -C "192.168.1.2@ssh"
# 将生成的ssh密钥复制到主节点的授权密钥。
$ cat $HOME/.ssh/id_rsa.pub >> $HOME/.ssh/authorized_keys
$ chmod 600 /root/.ssh/authorized_keys
# 在从节点生成秘钥
$ ssh-keygen -t rsa -P "" -C "192.168.1.3@ssh"
$ touch /root/.ssh/authorized_keys
$ chmod 600 /root/.ssh/authorized_keys
# 将主节点的ssh密钥复制到从属节点的授权密钥
$ 复制主节点的pubkey 到 从节点authorized_keys文件实现主节点直接登录从节点
5.编辑Hadoop配置文件。
# 在主服务器
$ vim /usr/local/hadoop-2.10.0/etc/hadoop/masters
master
$ vim /usr/local/hadoop-2.10.0/etc/hadoop/slaves
master
slave
#在从服务器
$ vim /usr/local/hadoop-2.10.0/etc/hadoop/masters
master
$ vim /usr/local/hadoop-2.10.0/etc/hadoop/slaves
slave6.在主从机上编辑core-site.xml,如下所示:
#在主从机上编辑core-site.xml,如下所示:
$ vim /usr/local/hadoop-2.10.0/etc/hadoop/core-site.xml
# fs.default.name 文件系统的名字。通常是NameNode的hostname与port
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://192.168.1.2:8020</value>
</property>
</configuration>7.在master上编辑hdfs-site.xml,如下所示:
#在master上编辑hdfs-site.xml,如下所示:
$ vim /usr/local/hadoop-2.10.0/etc/hadoop/hdfs-site.xml
$ mkdir /apps/hdfs/
# 参考https://www.cnblogs.com/duanxz/p/3799467.html
# replication 副本个数
# permissions 权限如果是,true则检查权限,否则不检查(每一个人都可以存取文件)
# namenode.name.dir 元数据存放位置,
# data.dir 数据节点的块本地存放目录,可以是以逗号分隔的目录列表,DataNode循环向磁盘中写入数据,每个DataNode可单独指定与其它DataNode不一样
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/apps/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/apps/hdfs/datanode1</value>
</property>
</configuration>
# 在从机上编辑hdfs-site.xml,如下所示:
$ vim /usr/local/hadoop-2.10.0/etc/hadoop/hdfs-site.xml
$ mkdir /apps/hdfs/
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/apps/hdfs/datanode2</value>
</property>
</configuration>8.在主从服务器上编辑mapred-site
#从配置文件夹中的模板复制mapred-site,在主从服务器复制mapred-site.xml
$ cp /usr/local/hadoop-2.10.0/etc/hadoop/mapred-site.xml.template /usr/local/hadoop-2.10.0/etc/hadoop/mapred-site.xml
#在主从服务器编辑 mapred-site.xml
$ vim /usr/local/hadoop-2.10.0/etc/hadoop/mapred-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>9.主从机器上编辑yarn-site.xml
$ vim /usr/local/hadoop-2.10.0/etc/hadoop/yarn-site.xml
# yarn.nodemanager.aux-services NodeManager上运行的附属服务。需配置成mapreduce_shuffle,才可运行MapReduce程序
#
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>10.格式化namenode(仅在主机上)
hadoop namenode -format11.启动所有守护程序(仅在主机上)。
/usr/local/hadoop-2.10.0/sbin/start-all.sh12.检查在主机和从机上运行的所有守护程序。
#主
$ jps
17889 SecondaryNameNode
17490 NameNode
18436 Jps
18089 ResourceManager
23147 QuorumPeerMain
18188 NodeManager
15452 Kafka
17663 DataNode
#从
29141 Jps
18519 QuorumPeerMain
29001 NodeManager
28876 DataNode13.命令参考
#停止所有
$ /usr/local/hadoop-2.10.0/sbin/stop-all.sh
#开启所有
$ /usr/local/hadoop-2.10.0/sbin/start-all.sh
#查看服务状态
$ jps
# 查看节点信息
$ hadoop dfsadmin -report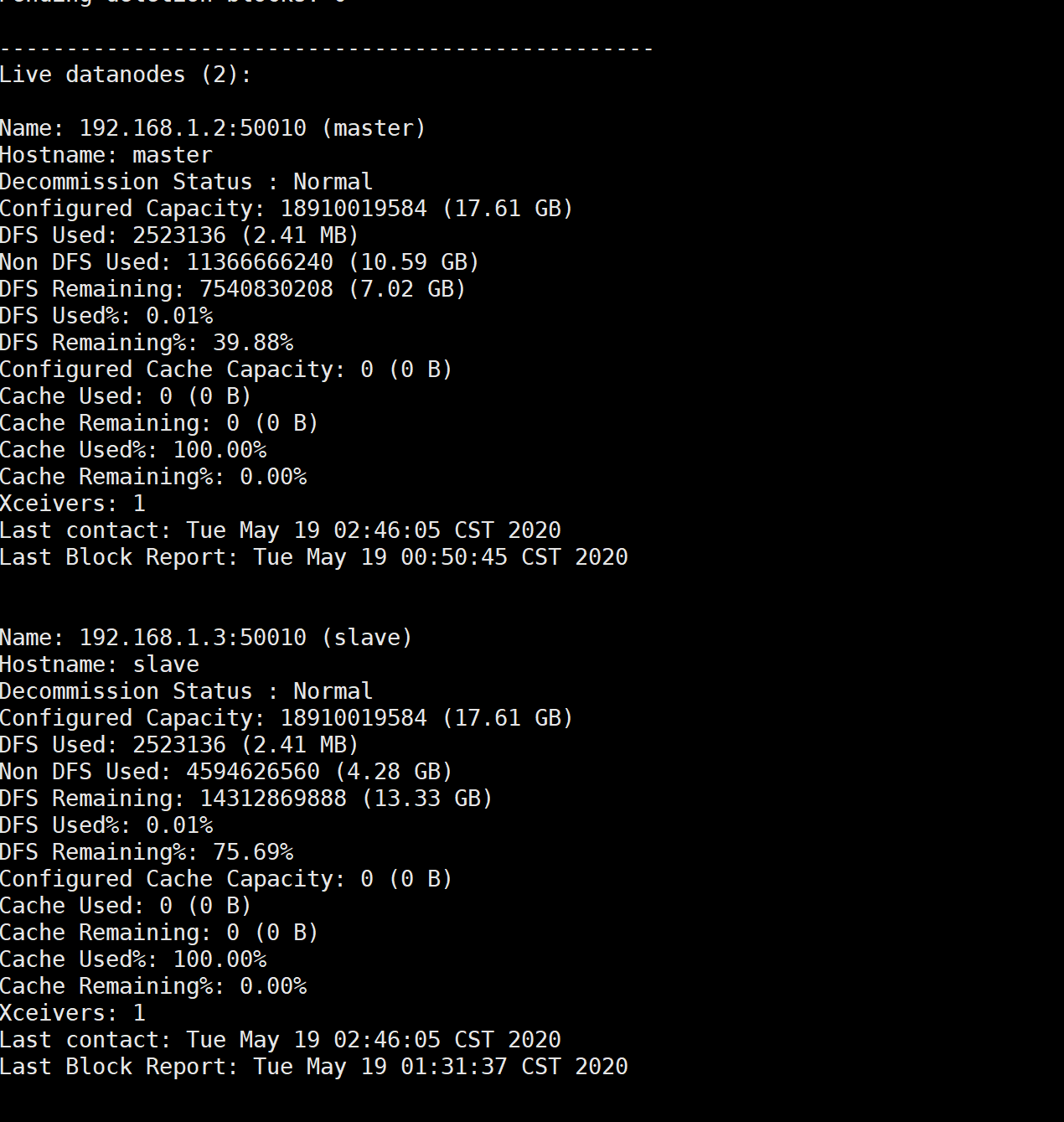
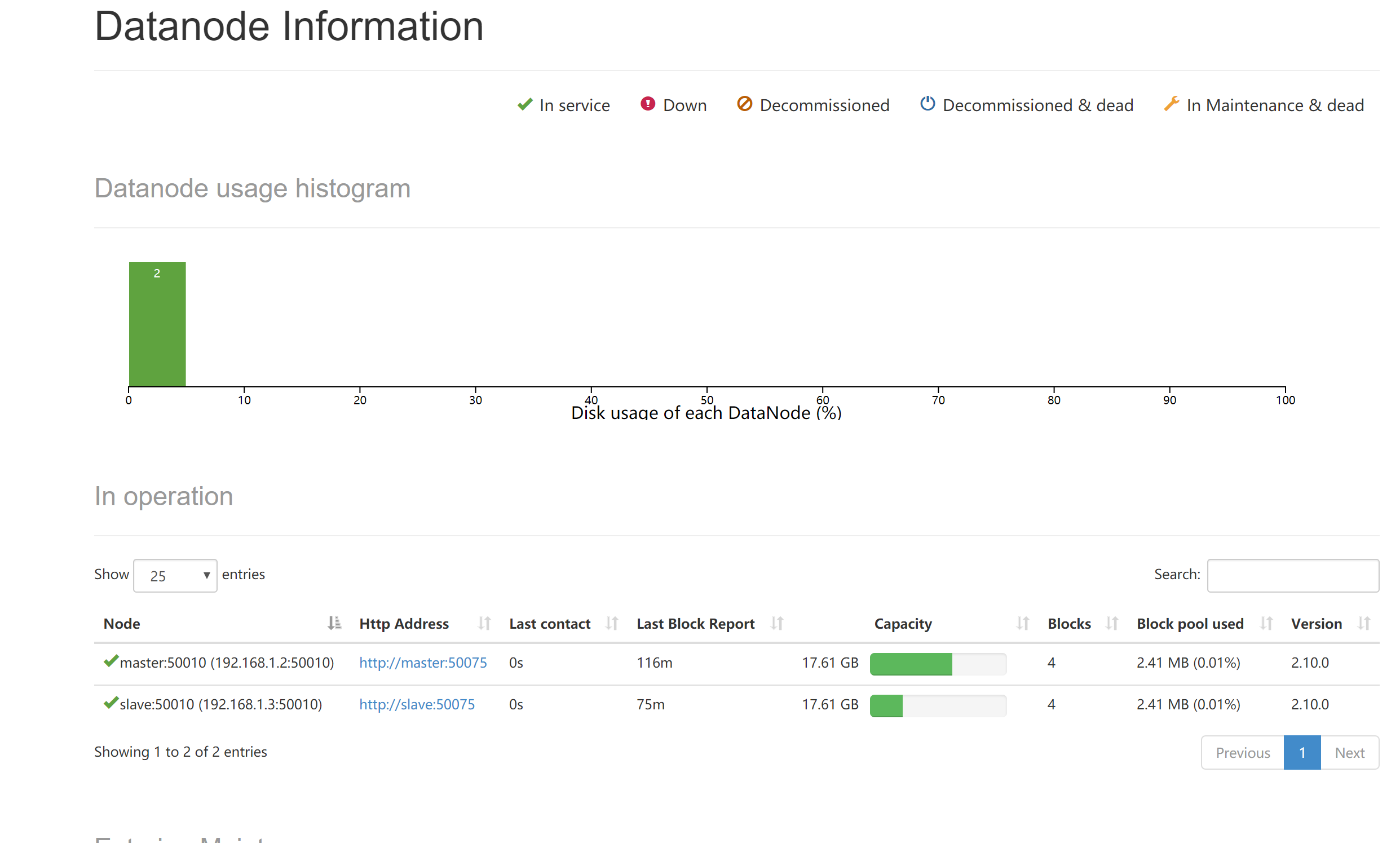
14.网页查看hdfs状态
http://192.168.1.2:50070/dfshealth.html#tab-overview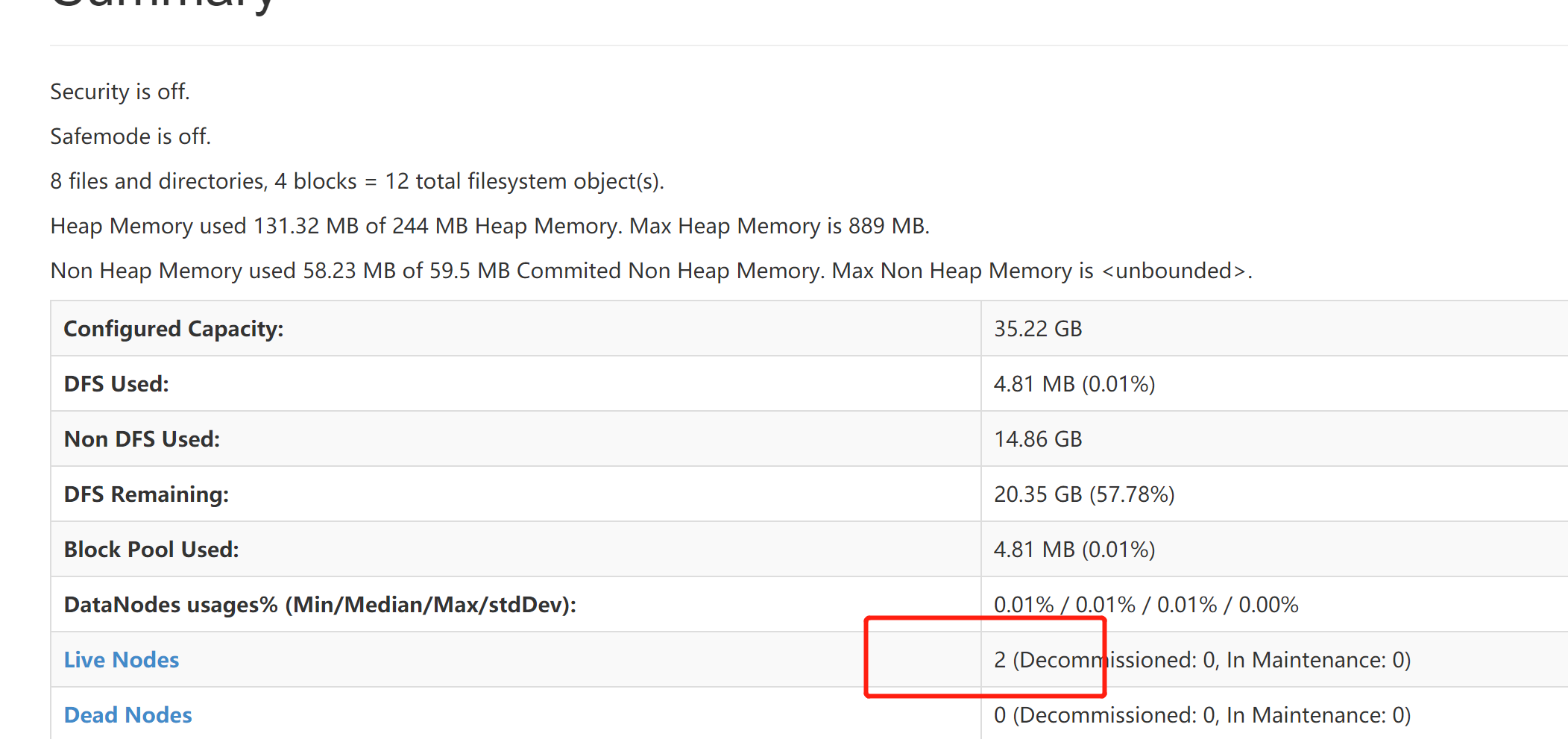
php调用hdfs
1.安装simpleenergy/php-webhdfs
# 参考:https://github.com/xaviered/php-WebHDFS/blob/master/README.md
$ composer require simpleenergy/php-webhdfs2.上传文件
<?php
$hdfs = new \org\apache\hadoop\WebHDFS(
'192.168.1.2',
'50070',
'root',
'192.168.1.2',
'50020',
true
);
var_dump($hdfs->create('test/test.png', 'android-icon-192x192.png'));
//result:true查看 http://192.168.1.2:50070/explorer.html#/test
| Permission | Owner | Group | Size | Last Modified | Replication | Block Size | Name | ||
|---|---|---|---|---|---|---|---|---|---|
| -rwxr-xr-x | root | supergroup | 15.36 KB | May 19 00:53 | 2 | 128 MB | android-icon-192×192.png |
3.读取文件并实时返回
url:http://test.php.com/www/test2/read_hdfs/filename/android-icon-192x192.png
<?php
//获取文件名
$filename = $this->request->param('filename');
$hdfs = new \org\apache\hadoop\WebHDFS(
'192.168.1.2',
'50070',
'root',
'192.168.1.2',
'50020',
true
);
//读取文件流,此种方式比较占内存,请修改php最大内存
$response = $hdfs->open('test/'.$filename);
//读取文件并返回文件mime,image/png
$finfo = new \finfo(FILEINFO_MIME_TYPE);
$ext = $finfo->buffer($response);
header( 'Content-Type:'.$ext);
echo $response;
exit;4.其他使用方法请参考
https://github.com/xaviered/php-WebHDFS/blob/master/README.md添加新机器
https://blog.csdn.net/ccorg/article/details/85013623
http://trimc-hdfs.blogspot.com/2014/11/adding-datanode-hdfs.html
https://blog.csdn.net/hzyyyyyyy/article/details/1029400131.创建dfs.hosts文件
`在主节点的/export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop目录下
创建一个文件为:dfs.hosts (HDFS可用节点的白名单)在文件中添加所有可用节点的主机名
`
[root@node02 hadoop]# vi dfs.hosts
node01
node02
node03
node042.编辑hdfs-site.xml文件
`在主节点的/export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop目录下
进入hdfs-site.xml文件中,在<configuration></configuration>标签中添加:`
<property>
<name>dfs.hosts</name>
<value>/export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop/dfs.hosts</value>
</property>
3.刷新NameNode
`在主节点中输入命令进行刷新NameNode`
[root@node02 hadoop]# hdfs dfsadmin -refreshNodes
Refresh nodes successful4.修改slave文件
`在主节点的/export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop目录下
进入slave文件,添加新增节点的主机名`
[root@node02 hadoop]# vim slaves
node01
node02
node03
node04
5.启动新增节点
[root@node023 sbin]# hadoop-daemon.sh start datanode
starting datanode, logging to /export/servers/hadoop-2.6.0-cdh5.14.0/logs/hadoop-root-datanode-node023.out
6.负载均衡
`让数据均匀负载所有机器`
[root@node02 sbin]# /usr/local/hadoop-2.10.0/sbin/start-balancer.sh移除datanode
# https://docs.cloudera.com/documentation/enterprise/5-9-x/topics/cdh_ig_decommision_datanodes.html1.创建一个名为 dfs.exclude
在每行上添加要停用的每个DataNode主机的名称。
$ vim /usr/local/hadoop-2.10.0/etc/hadoop/dfs.exclude
slave2.在要停用的DataNode上停止TaskTracker。
$ hadoop-daemon.sh stop tasktracker3.将以下属性添加到 hdfs-site.xml 在NameNode主机上。
$ vim /usr/local/hadoop-2.10.0/etc/hadoop/hdfs-site.xml
<property>
<name>dfs.hosts.exclude</name>
<value>/usr/local/hadoop-2.10.0/etc/hadoop/dfs.exclude</value>
</property>
$ vim /usr/local/hadoop-2.10.0/etc/hadoop/mapred-site.xml
<property>
<name>mapred.hosts.exclude</name>
<value>/usr/local/hadoop-2.10.0/etc/hadoop/dfs.exclude</value>
<final>true</final>
</property>4.刷新生效
hdfs dfsadmin -refreshNodes